上一节我们对爬虫程序的默认回调函数parse做了改写,提取的数据可以在Scrapy的日志中打印出来了,光打印肯定是不行的,还需要把数据存储,数据可以存到文件,也可以存到数据库,我们一一来看。
存储数据到文件
首先我们看看如何将数据存储到文件,在讲【Scrapy】Scrapy教程5——第一个Scrapy项目时,我们改写了prase函数,将首页存储到了一个shouye.html文件中,这便是我们的简单的数据存储,但这个存储方式是我们纯手写的代码,存的是整个页面,并非我们想要的数据。
这节主要讲存储数据,我们看下通过Scrapy命令直接存储数据,在这之前我们将parse函数修改下。
def parse(self, response): |
然后,我们在到命令行中,运行以下命令。
scrapy crawl shouye -o titles.json |
上面这条命令会将我们提取的数据存储到titles.json文件中,存储后的效果如下图所示。

我们会发现,存储的数据没有错,但是被整体存到了一个大的字典中,这不是我想要的结果,我只要数据一行一行的存储下来就好了,我们可以用以下命令。
scrapy crawl shouye -o titles.jsonl |
没错,我们换个存储格式,就可以了。

存储数据到数据库
上面这种方法存储简单的数据可以,对于复杂结构的数据存储,就要引入Items和pipelines了。
Items
我们爬取页面的目标就是将非结构化数据提取为结构化数据,而Item就是Scrapy提供的一个类,用于定义通用输出数据格式的。Scrapy可以将提取的数据,作为Item返回,类似python的键值对。
Item Types
Scrapy通过itemadapter支持字典、Item对象、数据类对象、attrs对象几种Item类型。
- 字典:类似Python的键值对字典
- Item对象:Item提供的一个类似dict的API,可以支持更高级的特性
- dataclass对象:允许定义具有字段名称的项目类,可以指定字段的类型和元数据
- attrs对象:允许定义具有字段名称的项目类,可以指定字段的类型和元数据
# 示例 |
通常我们用到的都是Item对象,只有当你想更深入一层去控制item时,需要使用到dataclass和attrs对象。
定义Item
Scrapy创建项目时,默认生成了items.py文件,我们在这里定义items。看下面这个例子。
import scrapy |
这是官网的一个例子,熟悉Django的朋友会注意到,Scrapy的Items定义和Django的Models很像,此外Scrapy Items因为不区分不同的字段类型,而变得更简单。注意看,例子中每个字段使用的都是Field对象,就是这么简单。
而Field对象的作用,是用来指定每个字段元数据的。比如上面示例中last_updated字段的序列化函数。你可以为每个字段指定任何类型的元数据,Field对象接受的值没有限制。因此,也没有所有可用元数据键的引用列表。
Field对象中定义的每个键都可以被不同的组件使用,并且只有这些组件知道该如何定义这些元数据。当然,也可以根据自己的需要在项目中定义和使用任何其他Field键。
Field对象的主要目标是提供一种在一个地方定义所有字段元数据的方法。通常,那些行为依赖于每个字段的组件使用某些字段键来配置该行为。您必须参考它们的文档以查看每个组件使用了哪些元数据键。
pipelines
爬虫被抓取后,会将提取的Item发送到Item Pipeline进行下一步的处理,Item Pipeline通过顺序执行的几个组件去处理。
每个组件是一个实现简单方法的python类,他们接受一个item并对其执行一个操作,同时决定是否继续通过管道或丢弃。使用Item Pipeline的典型用途有以下几种:
- 清洗HTML数据
- 验证抓取的数据(检查Item包含真正的字段)
- 查重
- 存储数据到数据库
每个pipeline组件中都要实现以下几个方法,即Python的函数,注意下面说的方法名不可以修改,否则无法正常执行。
process_item(self,item,spider)
- 每次执行Pipeline时都会执行的方法,是Pipeline中的核心方法,接收item数据,并做数据处理
- 参数
- self - 类自身
- item - item对象
- spider - 爬虫程序
- 返回值:必须返回item对象,或Deferred类型,或一个DropItem异常
open_spider(self,spider)
- 爬虫启动时被调用一次,可以讲一些需要提前执行的操作放到这里,比如建立数据库连接什么的
- 参数
- self - 类自身
- spider - 爬虫程序
close_spider(self,spider)
- 爬虫关闭时被调用一次,可以将一些需要结束时做的操作放到这里,比如关闭数据库连接等
- 参数
- self - 类自身
- spider - 爬虫程序
from_crawler(cls,crawler)
- 类方法,如果存在,则调用此类方法从Crawler创建一个Pipeline实例
- 参数
- cls - 类本身
- crawler - crawler使用的Pipeline,crawler对象提供对所有 Scrapy 核心组件的访问
- 返回值:必须是一个新的Pipeline实例
激活Item Pipeline
Item Pipeline默认是没有启用的,需要到settings.py文件中启用一下。
打开settings.py文件,找到ITEM_PIPELINES,可以看到,我们创建爬虫时,已经默认帮我们创建好一个默认的ITEM_PIPELINES,我们直接将前面的#取消掉即可。
ITEM_PIPELINES = { |
实战
上面将了两种存储数据的方式,文件存储很简单,实战就不过多赘述了。
实战部分主要练习下存储到数据库的方式,前面已经知道了Items和Pipelines,下面我们用这两个模块来练习下,将存储到文件的内容,存储到数据库中。
表的结构
既然是存到数据库,那就需要数据库中有表的存在,这里先创建个简单的表,就只存储文章标题和链接。那我们的表结构就很简单,只需要三个字段——id、title、url。
数据库的选择
表结构有了,那用哪个数据库呢?目前市面上的数据库有很多中,什么Oracle、MySQL、sqlite、MongDB等等,这里我为了方便,就使用sqlite3作为数据库了,因为这个不用单独安装引擎,直接使用Python自带的标准插件即可完成操作。
创建数据库和表
之所以选择SQLite数据库,就是因为它创建简单,我们直接在项目中创建的data文件夹,来存储我们的数据,然后在data文件夹中创建一个文件名为KS.sqlite的文件,KS就是KnowledgeSharing的缩写,.sqlite就是SQLite数据库的后缀。
然后我们使用数据库工具打开这个数据库文件,再创建个表,这里提供下数据库表创建的语句。
CREATE TABLE article ( |
封装数据库操作
为了方便操作数据库,我将和sqlite数据库打交道的操作,封装成一个类,方便后面多处的调用,也方便随时可以在其他项目中使用,具体的类内容可参见我的文章[[SQLite数据库操作]]。然后再在项目目录下创建一个lib文件夹,用于存放我们的数据库操作类,这里命名为sqlite_operate.py。
配置settings
在settings中除了要配置上面的ITEM_PIPELINE,还需要写上数据库的配置,如下
# SQLite数据库配置 |
编写items
我们打开items.py文件,可以看到已经为我们自动创建好KnowledgesharingItem类了,我们将下面的pass删除,修改为以下内容。
import scrapy |
编写pipelines
现在数据库有了,items也写好了,下面编写下我们的pipelines,打开pipelines.py文件,默认只有一个process_item方法,为了实现从settings那参数,还有初始化时实例化数据库,我们要增加__init__和from_crawler方法。
这里说明下,由于我单独封装了SQLite的访问类,因此打开数据库、关闭数据库的操作,我可以不用在Pipeline中写了,因此省去了open_spider和close_spider两个方法。
我们将pipelines.py文件改为以下代码。
from itemadapter import ItemAdapter |
改写parse文件
改写parse是最后一个步骤,我们要将item引入,把标题和链接存储到item的title和url中,将parse函数改写为下。
def parse(self, response): |
运行并查看存储结果
至此,所有需要修改的地方已经写好了,下面运行下爬虫,然后查看我们的数据库,会发现内容已经成功存到数据库中了。
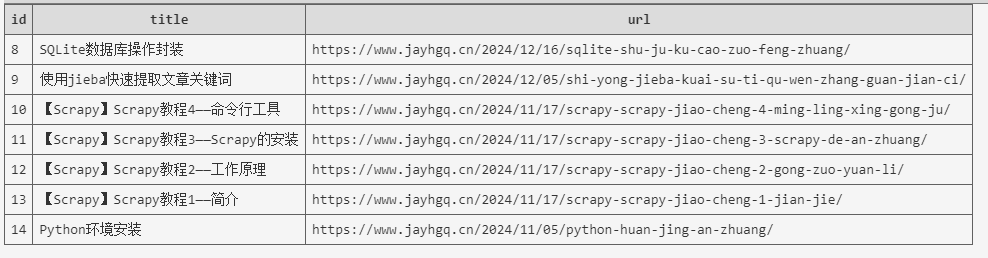
至此,两种存储数据的方式就唠叨完了。



