前一小节我们拿到了页面的数据,那页面中那么多内容,我们想要其中的部分内容,该如何获取呢?这就需要对我们下载到的数据进行解析,提取出来想要的数据,这节就讲讲如何提取数据。
引入
我们编辑保存下来的shouye.html文件看下,发现这是什么鬼,全是如下图的代码。

没错,html文件就是由一堆代码组成的,然后由浏览器进行渲染展示,那我们直接在浏览器中打开html文件是不是就可以了呢,来看看浏览器打开什么样。

感觉比纯代码好多了,但是我们再看看实际的网站页面什么样呢?
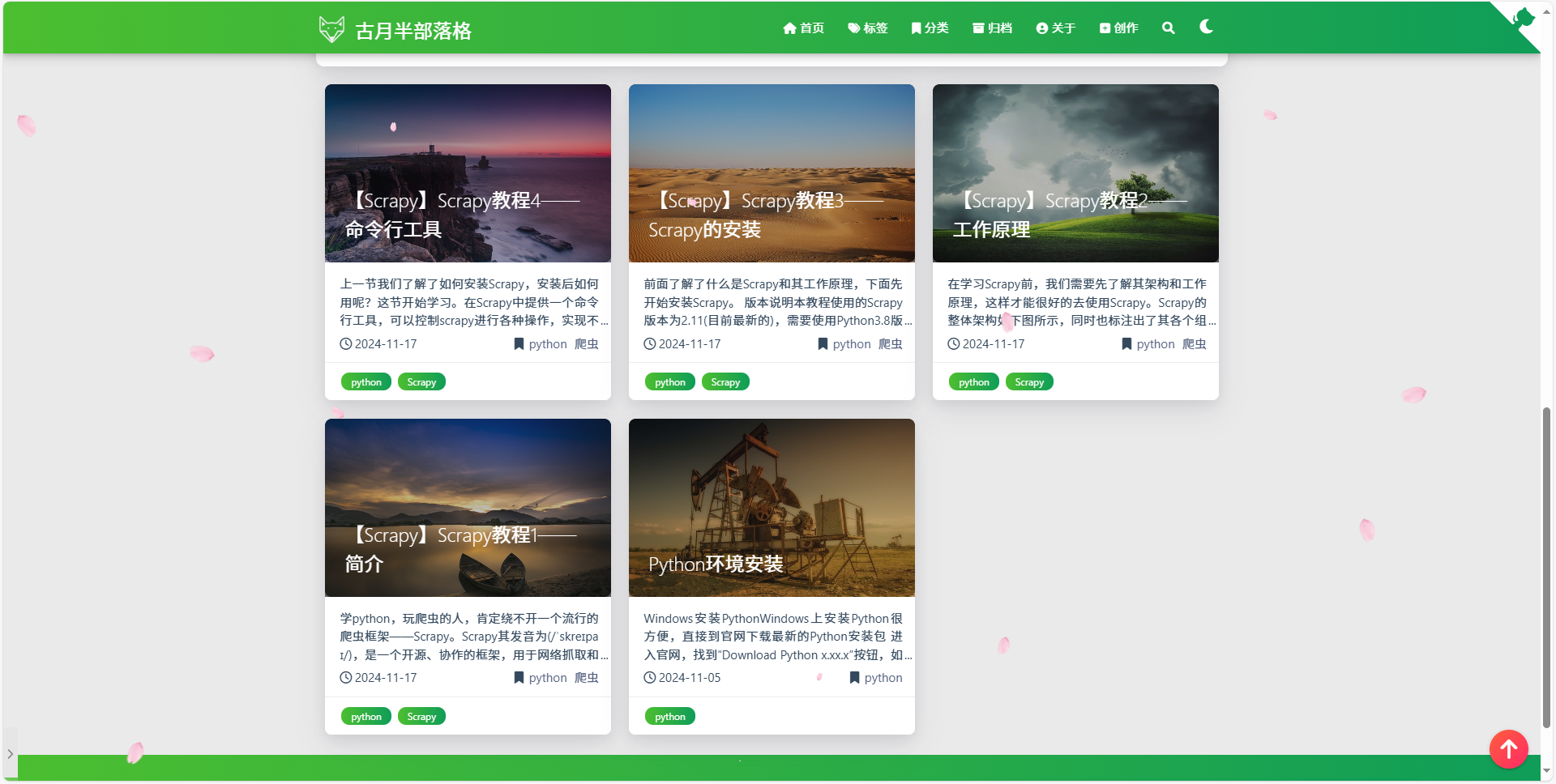
发现正式的网站漂亮很多,布局也很好,那这种效果怎么来的呢?学过web开发的朋友肯定知道,浏览器渲染网页时,不仅有html文件,还有CSS和JavaScript文件,来共同渲染出页面。CSS用来设定网页显示的效果,包括布局、样式、颜色等等,JavaScript用来实现网页的动画或特效,做爬虫我们要知道,我们默认爬取下来的只有html文件,不包括CSS和JS文件,但需要知道有这两个文件,因为有些网站不是静态的,数据是实时从数据库中拿的,而这些数据是通过JS来获取的,爬虫学深了后,就会知道如何从JS中拿数据了,后面有机会单独讲解这一块。
网站开发不在本教程的范围内,因此这里只提及,不会深度讲究,有需要系统学习的,可自己寻找相关文章或课程了解。
在哪提取数据
接着看如何提取数据,访问网站,我们能看到有几篇文章,我想找到这些文章的标题和链接,怎么找到它们呢?我们需要解析爬取到的页面,提取其中的想要的数据,说到这,就牵扯到Scrapy中一个重要的类——Spider类。
Spider类
Spider类是用来定义怎样抓取网站或一组站点的,包括如何爬取、如何提取结构化数据等。也就是说我们爬取什么网站,怎么爬取,如何解析这个网站都在Spider中定义。
这里说下Spider的抓取周期,有助于我们的理解:
- 生成初始的Requests爬取第一个URLs,并标识回调函数用于接收从requests中下载到的response。
- 通过start_requests()方法获得要执行的第一个请求,该方法默认从start_urls列表中获得 URL来生成请求,并将parse方法作为请求的默认回调函数。
- 在回调函数中,解析response,并返回Item对象、Request对象或一个可迭代的对象。
- 返回的Request对象也包含一个回调函数,稍后会被Scrapy下载,并用指定的回调函数对其处理
- 在回调函数中解析并生成items时,你可以使用Scrapy自带的Selectors,也可以用BeautifulSoup、lxml或其他你熟悉的工具
- 最后返回的items,一般会被持久化地保持到数据库,或用Feed exports导出到不同的文件。(Feed exports的相关介绍可参见Feed exports — Scrapy 2.12.0 documentation)
选择器Selectors
上面了解了Spider类的作用,从而也知道了,我们要想解析出文章的标题和链接,需要在爬虫程序下的回调函数中解析,也提到了,我们解析数据可以使用Scrapy自带的Selectors,也可以用BeautifulSoup、lxml或其他工具,本教程主要讲解的是Scrapy,因此BeautifulSoup、lxml工具不在此介绍,后面我会出单独的文章,感兴趣的朋友可以关注一下,这里我们主要说下Scrapy自带的Selectors。
Scrapy的Selectors是对parsel库的简单封装,为了方便对response对象做处理,关于parsel库可参考Parsel — Parsel 1.9.1 documentation。
Scrapy的Selectors包含两种选择器——CSS Selector和XPath Selector,下面分别介绍下。
CSS Selector
严格意义上来说,CSS不是一个选择器,CSS是一套用来控制HTML文件样式的语言,在Scrapy中可用其来定位内容,所以在Scrapy中我们管他叫CSS选择器。
下面是css的查找示例。
>>> response.css("title::text").get()
|
XPath Selector
XPath和CSS一样,XPath是一套在XML中查找元素的语言,可在xml文档中对元素和属性进行遍历,除了XML也可用于在HTML文件中快速查找定位,在Scrapy中可用其来定位内容,所以在Scrapy中我们管他叫XPath选择器。
下面是XPath的查找示例。
>>> response.xpath("//title/text()").get()
|
通过上面两个例子可以看出,两者都是查找标题的,但是使用了两种不同的选择器语法,CSS是通过样式来查找,XPath是通过节点来查找,两者的语法有所区别。后面会有专门的章节讲解选择器如何使用,这里不做过都介绍了,需要深入研究的可以看后面的选择器章节,下面我们直接进入实战。
验证选择器
知道了如何写选择器,那我们怎么验证我们的选择器写的对不对呢?
之前在命令行一章提到过,使用shell命令可以验证我们写的选择器对不对,下面我们来演示下。
首先访问我们的网站查看下网站标题为——古月半部落格。
然后我们打开装有Scrapy环境的终端,输入下面的命令。
>>> scrapy shell https://www.jayhgq.cn
2024-11-25 14:40:55 [scrapy.utils.log] INFO: Scrapy 2.11.2 started (bot: scrapybot)
(此处省略部分日志记录)
2024-11-25 14:40:56 [scrapy.core.engine] INFO: Spider opened
2024-11-25 14:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.jayhgq.cn> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x0000016732AB41A0>
[s] item {}
[s] request <GET https://www.jayhgq.cn>
[s] response <200 https://www.jayhgq.cn>
[s] settings <scrapy.settings.Settings object at 0x0000016732A4DBD0>
[s] spider <DefaultSpider 'default' at 0x167332cf230>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
|
当我们看到以上输出时,代表着Scrapy已经帮我们把提供的URL下载好,并可以通过命令行进行交互了,此外Scrapy还贴心的提供了我们可以使用的命令,然后我们再输入以下命令。
>>> response.css("title::text").get()
'古月半部落格'
|
这是用CSS Selector进行的标题选择。下面再输入以下命令,用XPath试下。
>>> response.xpath("//title/text()").get()
'古月半部落格'
|
可以发现,两个选择器找到的内容是一样的,这样我们就通过Scrapy的shell验证了我们写的选择器是可以正常使用,这就是一个验证的过程。
如何选择Selector
对于没有学过web开发的朋友,这里可能有点儿难度,所以简单的介绍下,我们的html页面是由很多组标签组成的文件,每个标签中会有个class属性,来定义要是用那种css样式的,我们在查找内容时,就可以通过选择器查找标签或class属性(即css)来定位我们想要的内容。
哪什么时候用CSS?什么时候用XPath?两者能不能一起用呢?是不是只有查class时用CSS,查标签时用XPath呢?
首先,我们要明确一点,不管是CSS还是XPath,他们都支持按标签和class属性查找,没有明确的界定查找标签只能用XPath,查找class只能用CSS,只是两种方式的语法不同。
其次,当class值比较唯一的时候,比如要找的内容使用的class相同,且没有其他内容的class和这个class一样,建议优先使用CSS查找。
最后,CSS和XPath是可以混用的,可以先用css定位一个大概的位置,然后用XPath定位具体内容。
实战
下面到了实战的环节,找到我们的爬虫程序——shouye,在默认的回调函数parse中提取首页中所有文章的标题和链接。
使用选择器查找
我们要想提取出数据,我们就得先查看网站的源码,知道要查找的内容在哪个标签中,我们才好定位。查看源码方式很简单,浏览器访问网站,然后右键-查看页面源代码即可打开。

找到我们要找的文章内容,可以发现所有文章的标题和链接都在<article>标签中,我们可以先定位到<article>标签,然后在这里面提取我们想要的内容。
response.css("article").getall()
response.xpath("//article").get()
|
找到了<article>标签,再往下看,找下每篇文章代码的相同点,发现每篇文章的标题和链接都在一个class="card"的标签中,那么我们把这个标签给都找出来。
response.css("article").css(".card").getall()
response.xpath("//article").xpath('.//div[@class="card"]').getall()
|
这样就拿到class="card"的标签后,其实如果自己查看下的话,整个页面有class="card"标签的也就6处,而我们的文章有5篇,其实我们省去找<article>标签也可以,只是所有class="card"标签中,第二个开始才是我们想要的内容,因此我们也可以把上面的语句缩减为
response.css(".card").getall()[1:]
response.xpath('//div[@class="card"]').getall()[1:]
|
获取的效果其实是一样的,都是把class="card"标签找到,那实际操作中,这就考验我们编写程序的人员对网站观察是否仔细了。
接下来我们看一个文章中的class="card"标签内容,如下。
<div class="card">
<a href="/2024/11/17/scrapy-scrapy-jiao-cheng-4-ming-ling-xing-gong-ju/">
<div class="card-image">
<img src="/medias/featureimages/2.jpg" class="responsive-img" alt="【Scrapy】Scrapy教程4——命令行工具">
<span class="card-title">【Scrapy】Scrapy教程4——命令行工具</span>
</div>
</a>
<div class="card-content article-content">
<div class="summary block-with-text">
上一节我们了解了如何安装Scrapy,安装后如何用呢?这节开始学习。在Scrapy中提供一个命令行工具,可以控制scrapy进行各种操作,实现不同功能。本节要先学习这个命令行工具,这样我们就能快速创建scrapy项目和爬虫程序,并进行相关调
</div>
<div class="publish-info">
<span class="publish-date">
<i class="far fa-clock fa-fw icon-date"/>2024-11-17
</span>
<span class="publish-author">
<i class="fas fa-bookmark fa-fw icon-category"/>
<a href="/categories/python/" class="post-category">python</a>
<a href="/categories/python/%E7%88%AC%E8%99%AB/" class="post-category">爬虫</a>
</span>
</div>
</div>
<div class="card-action article-tags">
<a href="/tags/python/">
<span class="chip bg-color">python</span>
</a>
<a href="/tags/Scrapy/">
<span class="chip bg-color">Scrapy</span>
</a>
</div>
</div>
|
可以发现,我们实际需要的内容只在第一个<a>标签中,我们再优化下代码,获取到第一个<a>标签。这里就不建议再使用CSS来查找了,因为使用CSS的话会直接查找到所有<a>标签,而下面几个<a>标签是用来访问categories和tags的,我们不需要,因此建议使用XPath来查找,因为XPath支持从当前节点往下查找,遇到第一个满足的就返回,因此代码可以做以下优化。
response.css(".card").xpath("./a").getall()
response.xpath('//div[@class="card"]').xpath("./a").getall()
|
如上所示,我们的CSS和XPath是可以混用的。再继续看,我们想要的链接在<a>标签的href属性中,标题在<span>标签的中,我们可以这样提取。
>>> response.css(".card").xpath("./a/@href").getall()
['/2024/11/17/scrapy-scrapy-jiao-cheng-4-ming-ling-xing-gong-ju/', '/2024/11/17/scrapy-scrapy-jiao-cheng-3-scrapy-de-an-zhuang/', '/2024/11/17/scrapy-scrapy-jiao-cheng-2-gong-zuo-yuan-li/', '/2024/11/17/scrapy-scrapy-jiao-cheng-1-
jian-jie/', '/2024/11/05/python-huan-jing-an-zhuang/']
>>> response.css(".card").xpath("./a").css("span::text").getall()
['【Scrapy】Scrapy教程4——命令行工具', '【Scrapy】Scrapy教程3——Scrapy的安装', '【Scrapy】Scrapy教程2——工作原理', '【Scrapy】Scrapy教程1——简介', 'Python环境安装']
|
爬虫中实现
那么我们看看在代码中如何实现呢?废话不多说,直接上代码。
def parse(self, response):
title_link_dict = []
for article in response.css(".card")[1:]:
title = article.xpath("./a").css("span::text").get()
link = self.start_urls[0] + article.xpath("./a/@href").get()
data = {"title":title, "link":link}
title_link_dict.append(data)
self.log(f"成功提取数据:{data}")
self.log(f"已提取数据:{title_link_dict}")
|
将回调函数parse的代码改写为以上代码后,再运行爬虫,我们可能看到日志中会有以下输出。
2024-11-27 17:33:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.jayhgq.cn> (referer: None)
2024-11-27 17:33:53 [shouye] DEBUG: 成功提取数据:{'title': '【Scrapy】Scrapy教程4——命令行工具', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-4-ming-ling-xing-gong-ju/'}
2024-11-27 17:33:53 [shouye] DEBUG: 成功提取数据:{'title': '【Scrapy】Scrapy教程3——Scrapy的安装', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-3-scrapy-de-an-zhuang/'}
2024-11-27 17:33:53 [shouye] DEBUG: 成功提取数据:{'title': '【Scrapy】Scrapy教程2——工作原理', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-2-gong-zuo-yuan-li/'}
2024-11-27 17:33:53 [shouye] DEBUG: 成功提取数据:{'title': '【Scrapy】Scrapy教程1——简介', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-1-jian-jie/'}
2024-11-27 17:33:53 [shouye] DEBUG: 成功提取数据:{'title': 'Python环境安装', 'link': 'https://www.jayhgq.cn/2024/11/05/python-huan-jing-an-zhuang/'}
2024-11-27 17:33:53 [shouye] DEBUG: 已提取数据:[{'title': '【Scrapy】Scrapy教程4——命令行工具', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-4-ming-ling-xing-gong-ju/'}, {'title': '【Scrapy】Scrapy教程3——
Scrapy的安装', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-3-scrapy-de-an-zhuang/'}, {'title': '【Scrapy】Scrapy教程2——工作原理', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-2-gong-z
uo-yuan-li/'}, {'title': '【Scrapy】Scrapy教程1——简介', 'link': 'https://www.jayhgq.cn/2024/11/17/scrapy-scrapy-jiao-cheng-1-jian-jie/'}, {'title': 'Python环境安装', 'link': 'https://www.jayhgq.cn/2024/11/05/python-huan-jing-an-
zhuang/'}]
2024-11-27 17:33:53 [scrapy.core.engine] INFO: Closing spider (finished)
|
此时,我们可以看到,已经成功的把标题和链接提取出来了,下一节我们讲讲如何把提取出来的数据进行存储。



