在学习Scrapy前,我们需要先了解其架构和工作原理,这样才能很好的去使用Scrapy。
Scrapy的整体架构如下图所示,同时也标注出了其各个组件和数据流。
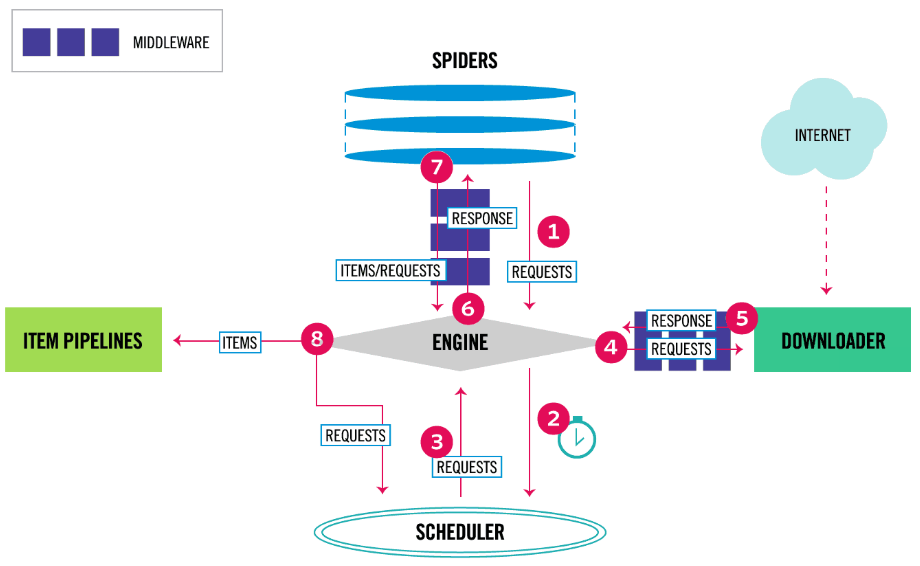
数据流
Scrapy的数据流由引擎控制,流程如下:
- 引擎Engine从爬虫Spiders中获得初始请求开始抓取。
- 引擎Engine在调度器Scheduler中调度请求,并准备对下一次的请求进行抓取。
- 调度器Scheduler返回下一个请求给引擎Engine。
- 引擎Engine通过下载器中间件Downloader Middleware发送请求到下载器Downloader
- 一旦下载器Downloader完成页面下载,将生成一个响应Response通过下载器中间件Downloader Middleware返回给引擎Engine。
- 引擎Engine收到下载器Downloader的响应,通过爬虫中间件Spiders Middleware发送给爬虫Spiders进行处理。
- 爬虫Spiders处理响应Response,并通过爬虫中间件Spiders Middleware返回处理后的Items,以及新的请求Request给引擎Engine。
- 引擎Engine发送处理后的Items给到项目管道Item Pipelines进行存储或其他处理,然后把处理后的请求Requests发送给调度器Scheduler,计划处理下一个可能抓取的请求。
- 流程从第3步重复,直到调度器Scheduler中没有更多的请求。
上面流程中提到了很多名词,比如引擎、调度器、下载器、爬虫、项目管道、中间件,这些是什么呢?都是Scrapy的组件。
组件
Scrapy包含了6大组件,分别是引擎(engine)、调度器(scheduler)、下载器(downloader)、爬虫(spiders)、项目管道(item pipelines)、中间件(middleware)。中间件中又分下载器中间件Downloader Middlewares和爬虫中间件Spider Middlewares
引擎Engine
引擎负责控制系统所有组件之间的数据流,并当某些操作发生时触发事件。
调度器Scheduler
调度器用来接收引擎发过来的请求,并把这些请求排入队列,当引擎需要时再返回。其作用是决定下一个要抓取的网址,并把重复的网址去除。
下载器Downloader
下载器负责取回网页内容(即响应response)返回给引擎,引擎把网页内容依次给爬虫。下载器是建立在twisted异步模型上的。
爬虫Spiders
爬虫是Scrapy的使用者自己编写的类,用来解析响应(response),并提取出项目(items)或额外的新请求。
项目管道Item Pipeline
项目管道负责处理由爬虫提取出来的项目,典型的任务包括清理、验证和持久化(比如存储到数据库)。
下载器中间件Downloader Middlewares
下载器中间件位于引擎和下载器之间,用来处理引擎到下载的请求,和下载器到引擎的响应。遇到以下情况时请使用下载器:
- 在请求发送到下载器之前处理请求
- 在响应发生到爬虫前修改接收到的响应
- 不把响应发送到爬虫,而是发送一个新请求
- 不获取网页的情况下把响应发送给爬虫
- 静默的删除一些请求
爬虫中间件Spider Middlewares
爬虫中间件位于引擎和爬虫之间,能够处理爬虫的输入(responses)和输出(items and requests)。当需要做以下事情时请使用爬虫中间件:
- 爬虫回调的内容处理后输出,包括修改、添加、删除请求requests或项目items
- 处理后开始请求start_requests
- 处理爬虫的异常
- 调用 errback 代替基于响应内容的某些请求的回调



